Перевод:
Set up a federated XMPP Chat Network with ejabberd, your own Google Talk Hangouts alternative
Автор: Реми ван Эст (Remy van Elst)
Примечания переводчика:
В оригинальной статье часто использовалось слово "федерализация" для того, чтобы подчеркнуть, что протокол XMPP не предполагает наличие единых серверов для всей сети, как это происходит в случае ICQ, WhatsApp, Viber или Telegram. XMPP предусматривает возможность создания множества сетей, у каждой из которых есть свои собственные серверы. Серверы каждой из сетей могут взаимодействовать с серверами других сетей на равноправных началах. То есть по аналогии с унитарными и федеральными государствами, ICQ можно назвать унитарной сетью, а XMPP можно назвать федеральной сетью. В переводе эти слова убраны, т.к. они не общеприняты и только запутывают. В качестве компенсации я добавил это примечание.
Содержание
- Зачем настраивать собственный сервер XMPP
- Информация
- Установка одиночного/ведущего узла ejabberd
- Установка ejabberd
- Настройка ejabberd
- Кластеризация ejabberd
- Подготовка ведущего узла
- Подготовка ведомых узлов
- Ошибки при кластеризации
- Записи DNS SRV
- Заключительное тестирование
В этом руководстве показано, как установить сервер ejabberd для обмена мгновенными сообщениями. В нём рассказывается о базовом одноузловом сервере ejabberd, а также о настройке кластера ejabberd. Руководство включает в себя примеры ошибок и записей DNS SRV.
Для установки собственного сервера XMPP можно воспользоваться услугами хостинга Inception Hosting VPS. Я пользуюсь их услугами и на мой взгляд этот хостинг очень стабильный, обладает высокой производительностью и низкими ценами.
Зачем настраивать собственный сервер XMPP
Существует несколько причин для настройки собственного сервера XMPP.
Может быть вы пользовались сервисом Google Talk или, как он теперь называется, Hangouts. Не так давно сервис Google прекратил поддерживать совместимость с XMPP. Если у вас есть контакты не на gmail, можно продолжать общаться с ними. Можно по-прежнему использовать открытый протокол, поддержка которого широко распространена и не станет частью закрытого программного и аппаратного обеспечения Google.
Возможно также, что вы хотите получить больший контроль за историей переписки. Выключите историю переписки ejabberd и воспользуйтесь
протоколом OTR, который позволит обеспечить вам полную тайну переписки (и Perfect Forward Secrecy - совершенно прямую секретность).
А может быть вы хотите пользоваться многопротокольными приложениями для обмена мгновенными сообщениями, такими как
Pidgin,
Psi+,
Empathy,
Adium, iChat/Messages или Miranda IM. На Android можно использовать
Xabber,
Beem или
OneTeam. Знаете ли вы, что большие компании, такие как Facebook, WhatsApp и Google, используют (или использовали ранее) XMPP в качестве основного протокола для обмена мгновенными сообщениями?
Или можете быть вы - системный администратор, которому нужна локальная система для обмена мгновенными сообщениями. У одного из моих клиентов есть кластер ejabberd, состоящий из 4 виртуальных машин с Debian 7 (по 2 гигабайта оперативной памяти на каждой). Кластер располагается на трёх площадках и в одном дата-центре, и обслуживает 12000 пользователей, из которых обычно одновременно подключено 6000.
XMPP - это прекрасный расширяемый протокол, дополнительную информацию о котором можно найти здесь:
https://en.wikipedia.org/wiki/XMPP
Информация
Эта статья проверена на Debian 7, Ubuntu 12.04 и 10.04, на OS X 10.8 Server. Все использовавшиеся серверы ejabberd были установлены через пакетный менеджер - либо через apt, либо через порты. Описанная конфигурация не проверялась, но также должна работать в Windows Server 2012 с ejabberd, собранном из исходных текстов на языке Erlang.
В статье используется домен example.org и сервер chat.example.org в качестве доменного имени XMPP-сервера. В разделе про кластеризацию используются серверы srv1.example.org и srv2.example.org. При настройке замените эти значения на ваши собственные.
Установка одиночного/ведущего узла ejabberd
Если вы хотите настроить одиночный узел ejabberd, без кластеризации, тогда воспользуйтесь только этим разделом и разделом про DNS. Если же вы хотите настроить кластер, тогда воспользуйтесь этим разделом, а затем перейдите к следующему.
Установка ejabberd
Это просто - для установки ejabberd воспользуйтесь пакетным менеджером:
apt-get install ejabberd
Также нужно установить несколько зависимостей среды поддержки Erlang.
Настройка ejabberd
Приступим к настройке сервиса ejabberd. Для начала остановим его:
/etc/init.d/ejabberd stop
Теперь запустите текстовый редактор для редактирования файлов конфигурации. Конфигурация ejabberd - это конфигурация на языке Erlang, поэтому комментарии начинаются не с #, а с %%. Также каждая опция в файле конфигурации завершается точкой (.).
vim /etc/ejabberd/ejabberd.cfg
Сначала добавим домен для обмена мгновенными сообщениями:
{hosts, ["example.org"]}.Если нужно больше доменов, можно добавить и их следующим образом:
{hosts, ["sparklingclouds.nl", "raymii.org", "sparklingnetwork.nl"]}.Эти доменные имена не являются именами серверов.
Далее объявим пользователя-администратора:
{acl, admin, {user, "remy", "example.org"}}.remy соответствует части до символа @ в идентификаторе XMPP, а example.org соответствует части после этого символа. Если вам нужно больше пользователей-администраторов - добавьте дополнительные строки ACL.
Теперь если вы хотите разрешить регистрироваться через XMPP-клиента, включите встроенную функцию регистрации:
{access, register, [{allow, all}]}.Если используется аутентификацию по данным из MySQL или LDAP, тогда возможность регистрации нужно отключить.
Мне нравится пользоваться общими списками контактов с группами списков контактов. Некоторые из моих клиентов используют общий список контактов для всех, так что никто не может добавить контакты, но могут видеть всех подключенных пользователей. Для этого нужно включить modsharedroster:
%% Сделайте это в блоке modules
{mod_shared_roster,[]},Если файл конфигурации вас устраивает, сохраните его и перезапустите ejabberd:
/etc/init.d/ejabberd restart
Теперь для проверки нашей конфигурации нужно зарегистрировать пользователя. Если функция встроенной регистрации была включена, можно воспользоваться XMPP-клиентом. Если же функция встроенной регистрации была выключена - воспользуйтесь командой ejabberdctl:
ejabberdctl register remy example.org 'passw0rd'
Теперь проверим учётную запись, воспользовавшись клиентом XMPP, таким как Pidgin, Psi+ или Empathy. Если вам удалось подключиться, можно продолжать настройку. Если же не удалось - проверьте журналы ejabberd, настройки пакетного фильтра и тому подобное, чтобы устранить проблему.
Кластеризация ejabberd
Отметим, прежде чем приступать к кластеризации ejabberd, вам нужен правильно работающий ведущий узел. Если ведущий узел не работает, то сначала исправьте его.
Важно: используемые вами модули должны быть одинаковыми на каждом из узлов кластера. Если вы используете аутентификацию LDAP/MySQL или shared_roster, или особые настройки MUC, или отправку сообщений не подключенным в данный момент пользователям, то при кластеризации эти настройки не будут действовать, пока не выставить их на всех узлах.
Теперь давайте приступим. Сначала займёмся настройкой ведущего узла, а затем перейдём к настройке ведомых узлов.
Подготовка ведущего узла
Остановим сервер на ведущем узле и отредактируем файл /etc/default/ejabberd:
vim /etc/default/ejabberd
Раскомментируем опцию с именем узла и заменим её значение на полное доменное имя узла:
ERLANG_NODE=ejabberd@srv1.example.org
Затем добавим внешний (публичный) IP-адрес, указав его как кортеж - с запятыми вместо точек:
INET_DIST_INTERFACE={20,30,10,5}Если ejabberd будет использоваться только в локальной сети, тогда укажите первичный адрес сетевой карты.
Мы собираемся удалить все таблицы mnesia. Они будут пересозданы при перезапуске ejabberd. Это проще, чем менять сами данные mnesia. Не делайте этого на уже настроенном узле, не сняв резервную копию с cookie-файла Erlang.
Для начала создадим резервную копию cookie-файла Erlang:
cp /var/lib/ejabberd/.erlang.cookie ~/
Затем удалим базу данных mnesia:
rm /var/lib/ejabberd/*
Теперь восстановим cookie-файл Erlang:
cp ~/.erlang.cookie /var/lib/ejabberd/.erlang.cookie
Чтобы удостовериться, что все процессы erlang были остановлены, завершите все процессы пользователя ejabberd принудительно. Делать это не обязательно, но диспетчер процессов epmd всё ещё может продолжать работать:
killall -u ejabberd
И теперь снова запустим ejabberd:
/etc/init.d/ejabberd start
Если после этого удалось подключиться и обмениваться сообщениями, тогда перейдите к следующей части - к настройке ведомых узлов.
Подготовка ведомых узлов
Сначала ведомые узлы нужно настроить так, как описано в первой части этой статьи. Для этого можно скопировать файлы конфигурации с ведущего узла.
Остановим сервер ejabberd:
/etc/init.d/ejabberd stop
Остановим сервер ejabberd на ведомом узле и отредактируем файл /etc/default/ejabberd:
vim /etc/default/ejabberd
Раскомментируем опцию с именем узла и заменим её значение на полное доменное имя узла:
ERLANG_NODE=ejabberd@srv2.example.org
Затем добавим внешний (публичный) IP-адрес, указав его как кортеж - с запятыми вместо точек:
INET_DIST_INTERFACE={30,40,20,6}Если ejabberd будет использоваться только в локальной сети, тогда укажите первичный адрес сетевой карты.
Теперь удалим все таблицы mnesia:
rm /var/lib/ejabberd/*
Скопируем cookie-файл с ведущего узла ejabberd при помощи cat и vim или через scp:
# На ведущем узле
cat /var/lib/ejabberd/.erlang.cookie
HFHHGYYEHF362GG1GF
# На ведомом узле
echo "HFHHGYYEHF362GG1GF" > /var/lib/ejabberd/.erlang.cookie
chown ejabberd:ejabberd /var/lib/ejabberd/.erlang.cookie
Теперь приступим к компиляции модуля easy_cluster на Erlang. Это очень маленький модуль, который добавляет к оболочке Erlang команду для более простого добавления кластера. Вместо этих команд в оболочке Erlang можно выполнить сами Erlang-функции в отладочной оболочке, но я считаю, что модуль удобнее и его использование уменьшает вероятность ошибок:
vim /usr/lib/ejabberd/ebin/easy_cluster.erl
Добавьте следующее содержимое:
-module(easy_cluster).
-export([test_node/1,join/1]).
test_node(MasterNode) ->
case net_adm:ping(MasterNode) of 'pong' ->
io:format("server is reachable.~n"); %% Сервер доступен
_ ->
io:format("server could NOT be reached.~n") %% Сервер не доступен
end.
join(MasterNode) ->
application:stop(ejabberd),
mnesia:stop(),
mnesia:delete_schema([node()]),
mnesia:start(),
mnesia:change_config(extra_db_nodes, [MasterNode]),
mnesia:change_table_copy_type(schema, node(), disc_copies),
application:start(ejabberd).Сохраните его и скомпилируйте в работающий Erlang-модуль:
cd /usr/lib/ejabberd/ebin/
erlc easy_cluster.erl
Теперь проверим, что компиляция была успешной:
ls | grep easy_cluster.beam
Если вы увидели файл, значит компиляция завершилась успешно. Дополнительную информацию по модулю можно найти здесь:
https://github.com/chadillac/ejabberd-easy_cluster/
Теперь приступим к присоединению узла кластера к ведущему узлу. Убедитесь что ведущий узел запущен и работает. Также удостоверьтесь, что cookie-файлы Erlang синхронизированы.
На ведомом узле запустите интерактивную оболочку ejabberd:
/etc/init.d/ejabberd live
Эта команда запустит оболочку Erlang, после чего оболочка начнёт выводить информацию. Когда она прекратит вывод, можно нажать Enter и получить приглашение. Введите следующую команду, чтобы проверить, что ведущий узел достижим:
easy_cluster:test_node('ejabberd@srv1.example.org').Вы должны получить сообщение "server is reachable" - "Сервер доступен". Если это так, то продолжим.
Введём следующую команду, чтобы действительно присоединить узел:
easy_cluster:join('ejabberd@srv1.example.org').Вот пример вывода при успешной проверке и подсоединении узла:
/etc/init.d/ejabberd live
*******************************************************
* To quit, press Ctrl-g then enter q and press Return *
*******************************************************
Erlang R15B01 (erts-5.9.1) [source] [async-threads:0] [kernel-poll:false]
Eshell V5.9.1 (abort with ^G)
=INFO REPORT==== 10-Jun-2013::20:38:15 ===
I(<0.39.0>:cyrsasl_digest:44) : FQDN used to check DIGEST-MD5 SASL authentication: "srv2.example.org"
=INFO REPORT==== 10-Jun-2013::20:38:15 ===
I(<0.576.0>:ejabberd_listener:166) : Reusing listening port for 5222
=INFO REPORT==== 10-Jun-2013::20:38:15 ===
I(<0.577.0>:ejabberd_listener:166) : Reusing listening port for 5269
=INFO REPORT==== 10-Jun-2013::20:38:15 ===
I(<0.578.0>:ejabberd_listener:166) : Reusing listening port for 5280
=INFO REPORT==== 10-Jun-2013::20:38:15 ===
I(<0.39.0>:ejabberd_app:72) : ejabberd 2.1.10 is started in the node 'ejabberd@srv2.example.org'
easy_cluster:test_node('ejabberd@srv1.example.org').
server is reachable.
ok
(ejabberd@srv2.example.org)2> easy_cluster:join('ejabberd@srv1.example.org').
=INFO REPORT==== 10-Jun-2013::20:38:51 ===
I(<0.39.0>:ejabberd_app:89) : ejabberd 2.1.10 is stopped in the node 'ejabberd@srv2.example.org'
=INFO REPORT==== 10-Jun-2013::20:38:51 ===
application: ejabberd
exited: stopped
type: temporary
=INFO REPORT==== 10-Jun-2013::20:38:51 ===
application: mnesia
exited: stopped
type: permanent
=INFO REPORT==== 10-Jun-2013::20:38:52 ===
I(<0.628.0>:cyrsasl_digest:44) : FQDN used to check DIGEST-MD5 SASL authentication: "srv2.example.org"
=INFO REPORT==== 10-Jun-2013::20:38:53 ===
I(<0.1026.0>:ejabberd_listener:166) : Reusing listening port for 5222
=INFO REPORT==== 10-Jun-2013::20:38:53 ===
I(<0.1027.0>:ejabberd_listener:166) : Reusing listening port for 5269
=INFO REPORT==== 10-Jun-2013::20:38:53 ===
I(<0.1028.0>:ejabberd_listener:166) : Reusing listening port for 5280
ok
(ejabberd@srv2.example.org)3>
=INFO REPORT==== 10-Jun-2013::20:38:53 ===
I(<0.628.0>:ejabberd_app:72) : ejabberd 2.1.10 is started in the node 'ejabberd@srv2.example.org'Покиньте оболочку Erlang дважды нажав Ctrl+C. Теперь остановите ejabberd и запустите его снова:
/etc/init.d/ejabberd restart
Теперь в административном веб-интерфейсе можно проверить, что узел успешно присоединился к кластеру:
http://srv1.example.org:5280/admin/nodes/
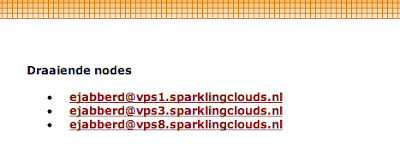
Если будут отображены другие узлы, значит всё готово. Если нет, тогда убедитесь, что выполнили каждый шаг и обратитесь к разделу ниже с описанием решений проблем.
Повторите описанные выше шаги для каждого из узлов, которые нужно добавить. Вы можете добавить столько узлов, сколько захотите.
Ошибки при кластеризации
В процессе настройки кластера могут произойти ошибки. Ниже перечислены примечания по встречавшимся мне ошибкам.
- Перезапуск ejabberd не приводит к перезапуску epmd (демона Erlang)
- избыточное решение: killall -u ejabberd
- ejabberd возвращает ошибки с именем узла
- убедитесь в правильности настройки имени узла (имя узла - srv1.example.com).
- ejabberd возвращает ошибки несогласованности базы данных
- создайте резервную копию cookie-файла Erlang (/var/lib/ejabberd/.erlang.cookie), а затем удалите содержимое каталога /var/lib/ejabberd, чтобы mnesia перестроила таблицы.
- ejabberd сообщает "Попытка подключения от запрещённого узла" - "Connection attempt from disallowed node"
- убедитесь в корректности cookie-файла Erlang (/var/lib/ejabberd/.erlang.cookie). Перед вставкой содержимого в редакторе vim перейдите в режим вставки...
Записи DNS SRV
Записи DNS SRV используются XMPP-клиентами и другими XMPP-серверами для поиска правильного адреса сервера. Например, Алиса настраивает своего XMPP-клиента на адрес alice@example.org. Её клиент ищет запись SRV и узнаёт, что сервер для обмена мгновенными сообщениями находится по адресу chat.example.org. Боб настраивает своего клиента на адрес bob@bobsbussiness.com и добавляет Алису в список контактов. XMPP-сервер домена bobsbussiness.com ищет запись SRV и узнаёт, что он должен установить подключение типа сервер-к-серверу по адресу chat.example.org, чтобы дать Бобу возможность переписываться с Алисой.
Конфигурация BIND 9 будет выглядеть следующим образом:
; XMPP
_xmpp-client._tcp IN SRV 5 0 5222 chat.example.org.
_xmpp-server._tcp IN SRV 5 0 5269 chat.example.org.
_jabber._tcp IN SRV 5 0 5269 chat.example.org.
Основные записи SRV указывают порты для подключения клиентов и для подключений типа сервер-к-серверу, а третья запись - это устаревший формат записей Jabber. Если используется хостинг DNS, введите эти записи в панели администрирования или посоветуйтесь с технической поддержкой хостинга.
Для проверки правильности SRV-записей можно воспользоваться командой dig:
dig _xmpp-client._tcp.example.org SRV
dig _xmpp-server._tcp.example.org SRV
Или если на вашем компьютере установлена операционная система Windows, тогда воспользуйтесь nslookup:
nslookup -querytype=SRV _xmpp-client._tcp.example.org
nslookup -querytype=SRV _xmpp-server._tcp.example.org
Если результат будет похожим на приведённый ниже, значит всё настроено верно:
;; QUESTION SECTION:
;_xmpp-client._tcp.raymii.org. IN SRV
;; ANSWER SECTION:
_xmpp-client._tcp.raymii.org. 3600 IN SRV 5 0 5222 chat.raymii.org.
На самом же деле в моём случае у chat.raymii.org имеется несколько A-записей:
;; ADDITIONAL SECTION:
chat.raymii.org. 3600 IN A 84.200.77.167
chat.raymii.org. 3600 IN A 205.185.117.74
chat.raymii.org. 3600 IN A 205.185.124.11
Но если был настроен только один узел, то это будет либо запись CNAME, либо одна запись A/AAAA.
Заключительное тестирование
Чтобы протестировать, что всё работает, можно добавить в список контактов XMPP-бота Duck Duck Go. Если вам без проблем удалось добавить его и поговорить с ним, то значит всё было сделано верно. Адрес бота - im@ddg.gg.






